
Building AI Apps with Elixir
Building AI Apps with Elixir
I recently gave my first talk at ElixirConf 2023. I had a great time meeting other Elixir fans (there are dozens of us! dozens!) and I'm really happy with the reaction people had.
Watching a 30 min talk isn't for everyone. So, I followed Simon Willison's excellent advice and created an annotated version of my talk. I downloaded the audio file, transcribed it with Whisper, asked Claude to take out my ums and ahs, and then copied in my slides using Simon's tool.
If you want to see my favorite part of the talk, skip to the Shinstagram demo.
- About Me
- Three patterns
- The Magic AI Box
- Magic AI Box Demo
- The Gen Server Generator
- Agents
- Shinstagram Demo
- What do I put in the AI box?
- Conclusion
- Thanks to...
- Questions? Feedback?

Almost exactly three years ago I was on Hacker News and I came across Chris McCord's talk on building a Twitter clone using Phoenix Live View. I'd never used Elixir before and never heard of Live View, but I noticed the comments on Hacker News were really positive and that is an unusual phenomenon. So I was like, hmm, I'll check this thing out.
And from pretty much then on, I've been hooked on Elixir and LiveView. And so it's really cool for me that almost exactly three years later, I'm speaking at the biggest Elixir conference. And as a side note, that the Twitter clone that I built ended up becoming ShlinkedIn, which is, well, the way I pitch it is it's LinkedIn, but serious.
This talk though is not about Shlinkedin. It is about building AI apps with Elixir. As you may have heard, AI is really hot right now. But what I want to talk about is Elixir and AI. Because everyone's talking about AI, but not enough people are talking about the ways you can use Elixir and AI.

My name is Charlie Holtz, and I'm a hacker in residence at Replicate. And Replicate is a startup that makes it really easy to run machine learning models using API, and it runs in the cloud. I'll get more into what Replicate does later, but I'm a hacker in residence there, which basically means I build stuff with AI and then talk about it. And that actually is my official title, hacker in residence. When I was joining Replicate, the CEO asked me to give myself any title I wanted. So I said, okay, I'm CEO.
And then he said, actually, you have to pick something else. And I went with hacker in residence. And so that's what we stuck with. And I built dozens of AI apps now, where I define AI apps, where any app where the core logic uses AI of some kind. And I try and build as many as I can with Phoenix and LiveView and Elixir.

So this talk is about three patterns that I've noticed come up again and again as I'm building these apps. And I want to give you these patterns as a way to get started building AI apps yourself. And I think it's going to make you a lot faster at building AI apps. And I also hope it will inspire you with all the cool things you can build yourself. And the three patterns are called the Magic AI Box, the Gen Server Generator, and Agents.
Let's start with the magic AI box. The way I've been thinking about AI is it's, I'm not worrying about how it works or how to be a machine learning engineer or any of that. That's for other people to figure out. I wanna think about all the ways I can use AI. And so I like to imagine AI as this magical box that I can put an input into and it does something really cool with that input and give me the output. For example,
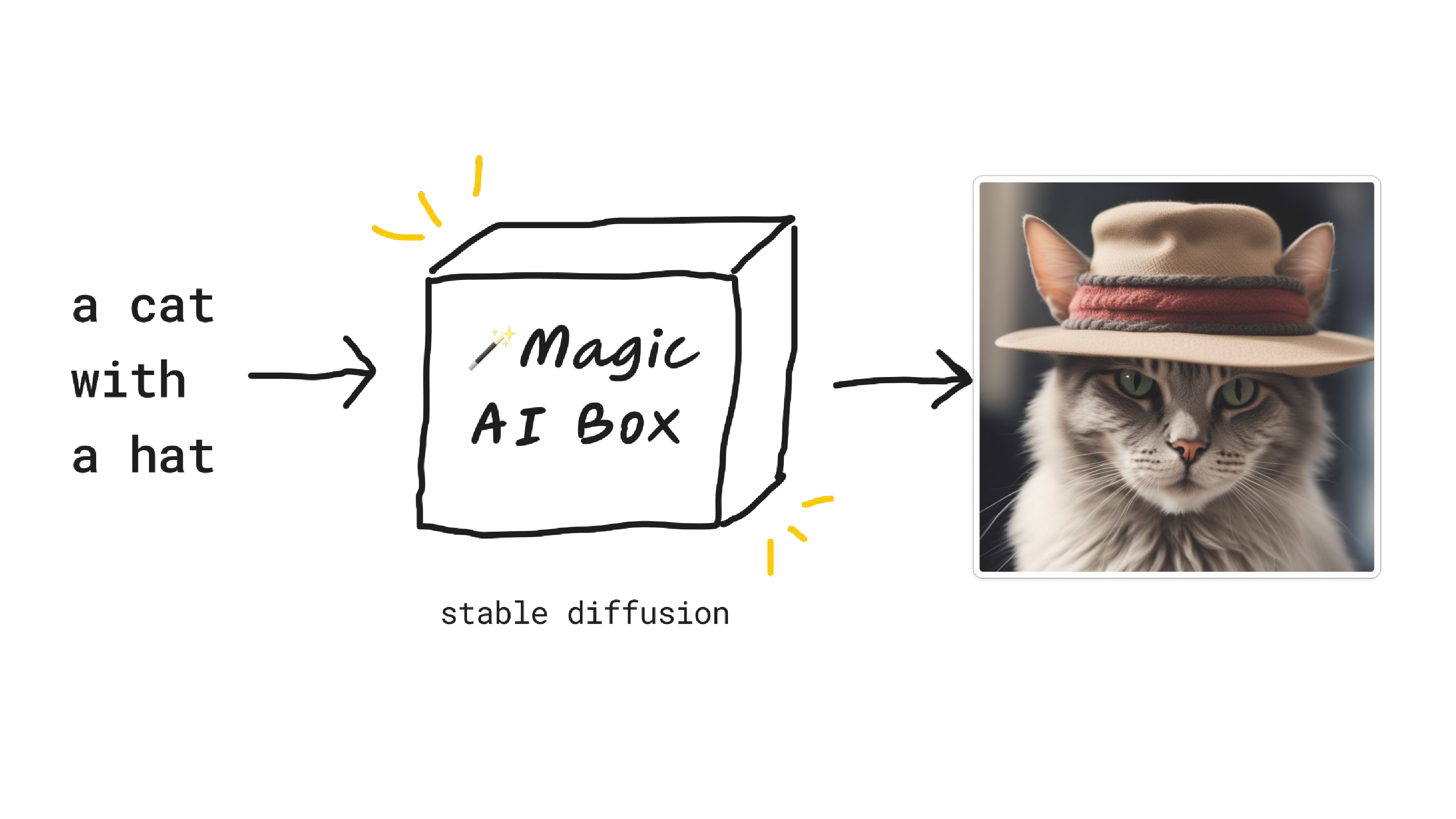
In this case, I put in the text input, a cat with a hat. It goes to our magic AI box, which we can think of as a module or a function or an API. In this case, we have stable diffusion inside that magic AI box, which if you haven't heard of it, it's like mid-journey or Dolly. It's a text-to-image model. So we put in a cat with a hat into our magic AI box, and we get out a cool-looking cat with a hat.
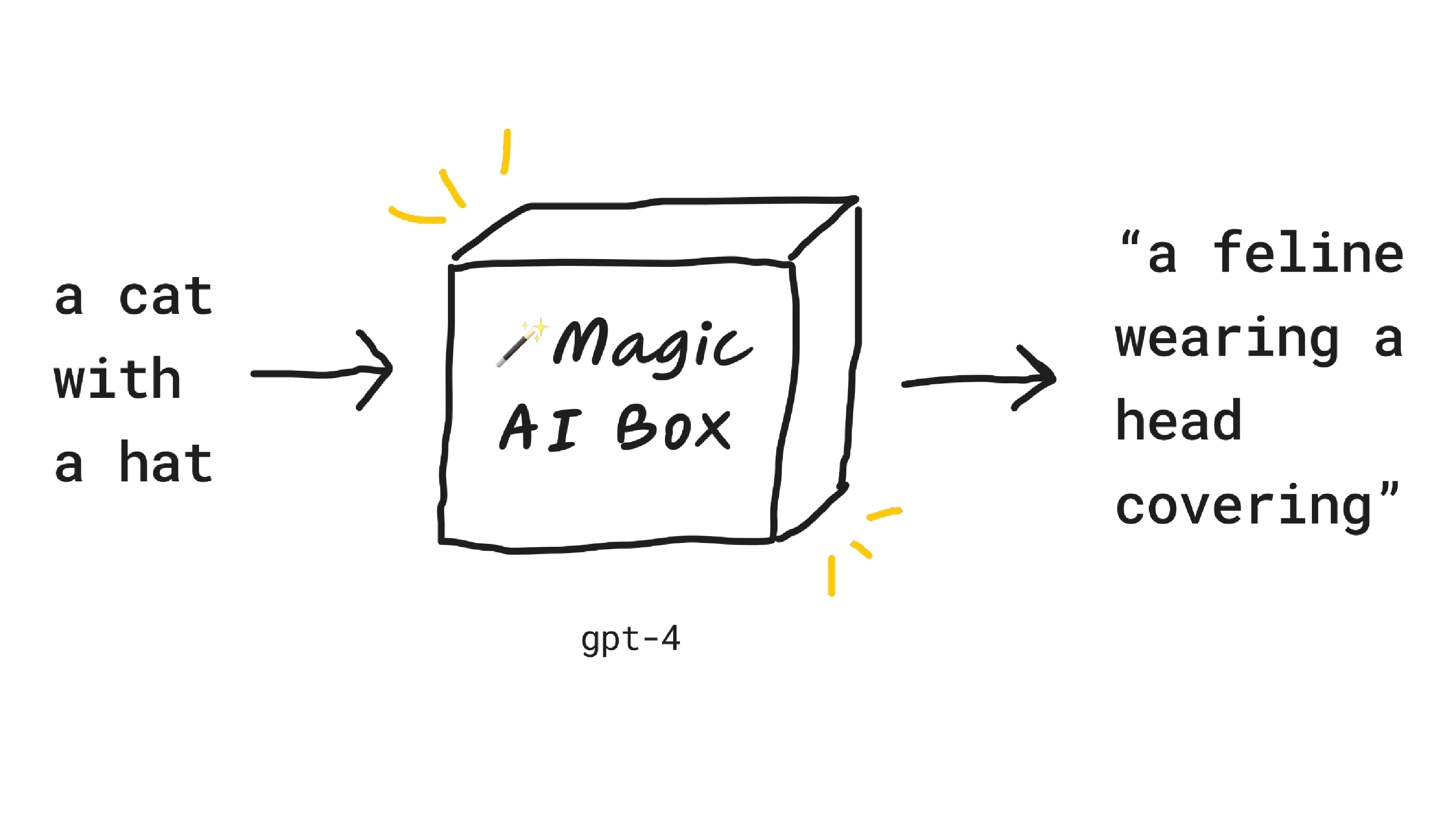
We'd also put GPT-4 inside this box, which I'm sure you've heard of, a text model from OpenAI. In this case, we put in a cat with a hat and we get a feline wearing a head covering.
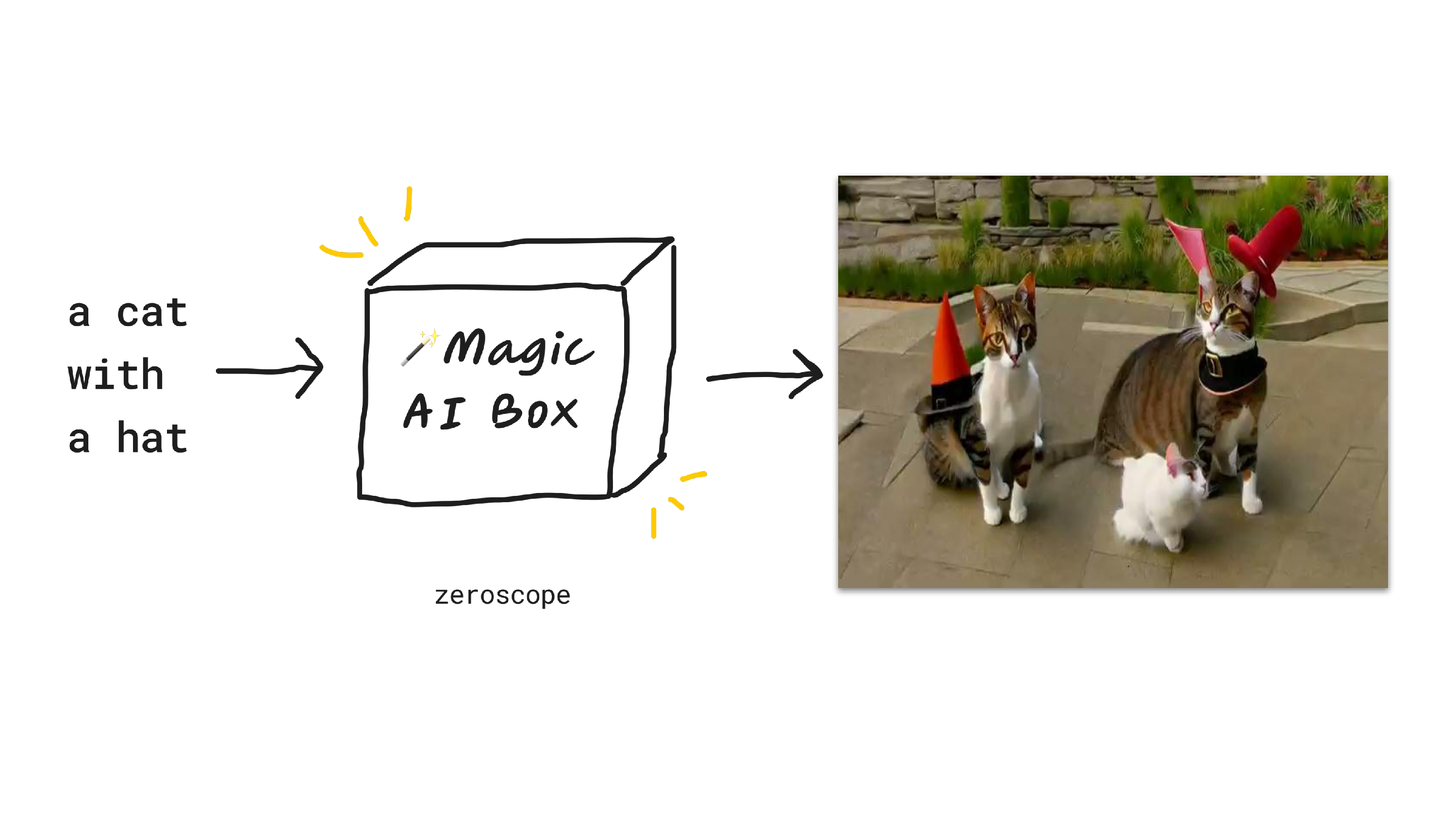
We could also put in a text-to-video model. These are pretty new right now and very primitive compared to the other models, but it's pretty amazing to me that you can put in text to this model and then you get out something that looks like, I'll play the video, a two-second video of cats sort of wearing hats. It's close enough.
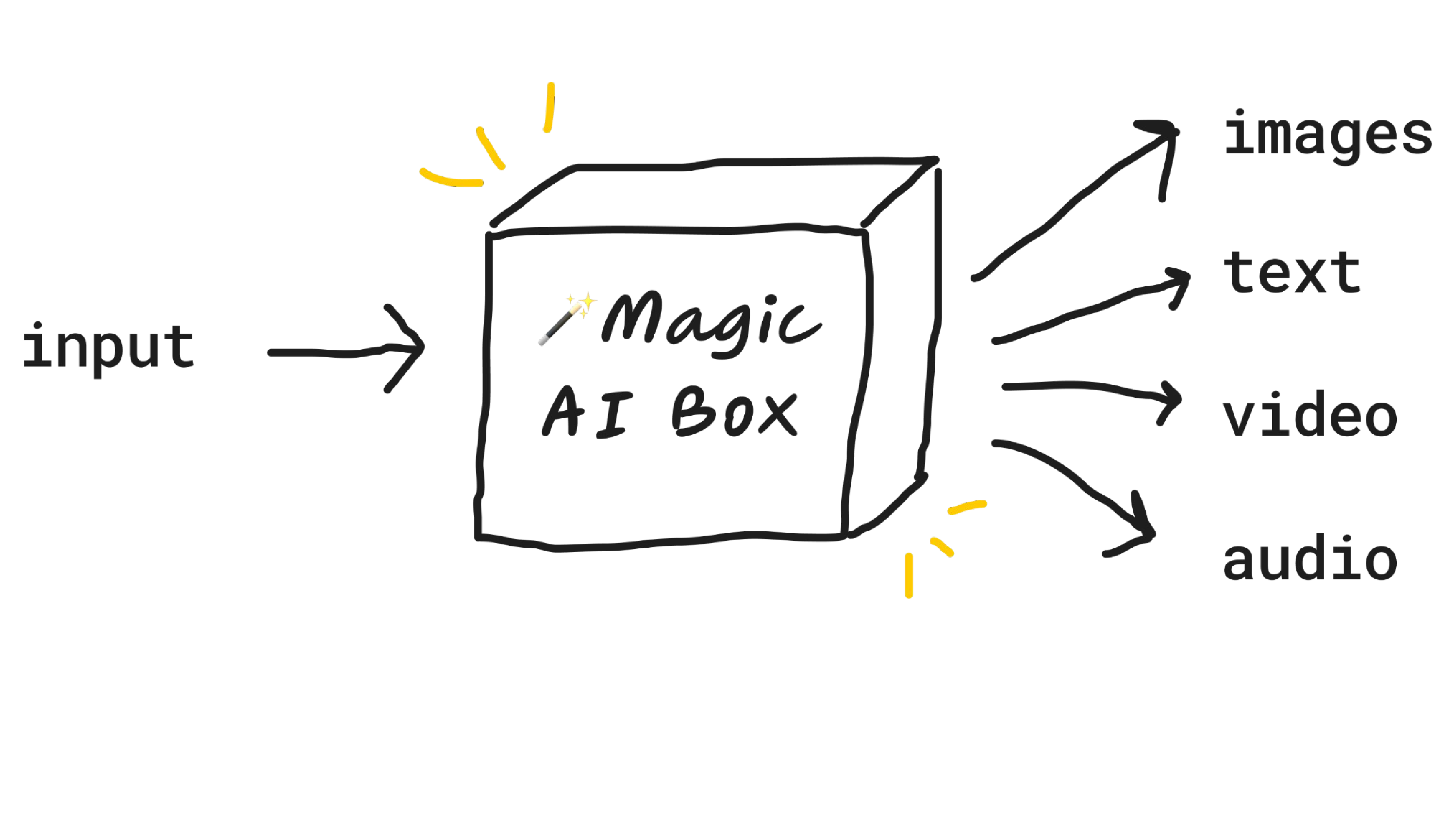
The point is, you can put in all kinds of things into this magical AI box, get all kinds of outputs back. You can get images, you can get text, you can get video, you can get audio, you can even get QR codes, which I'll show you at the end.
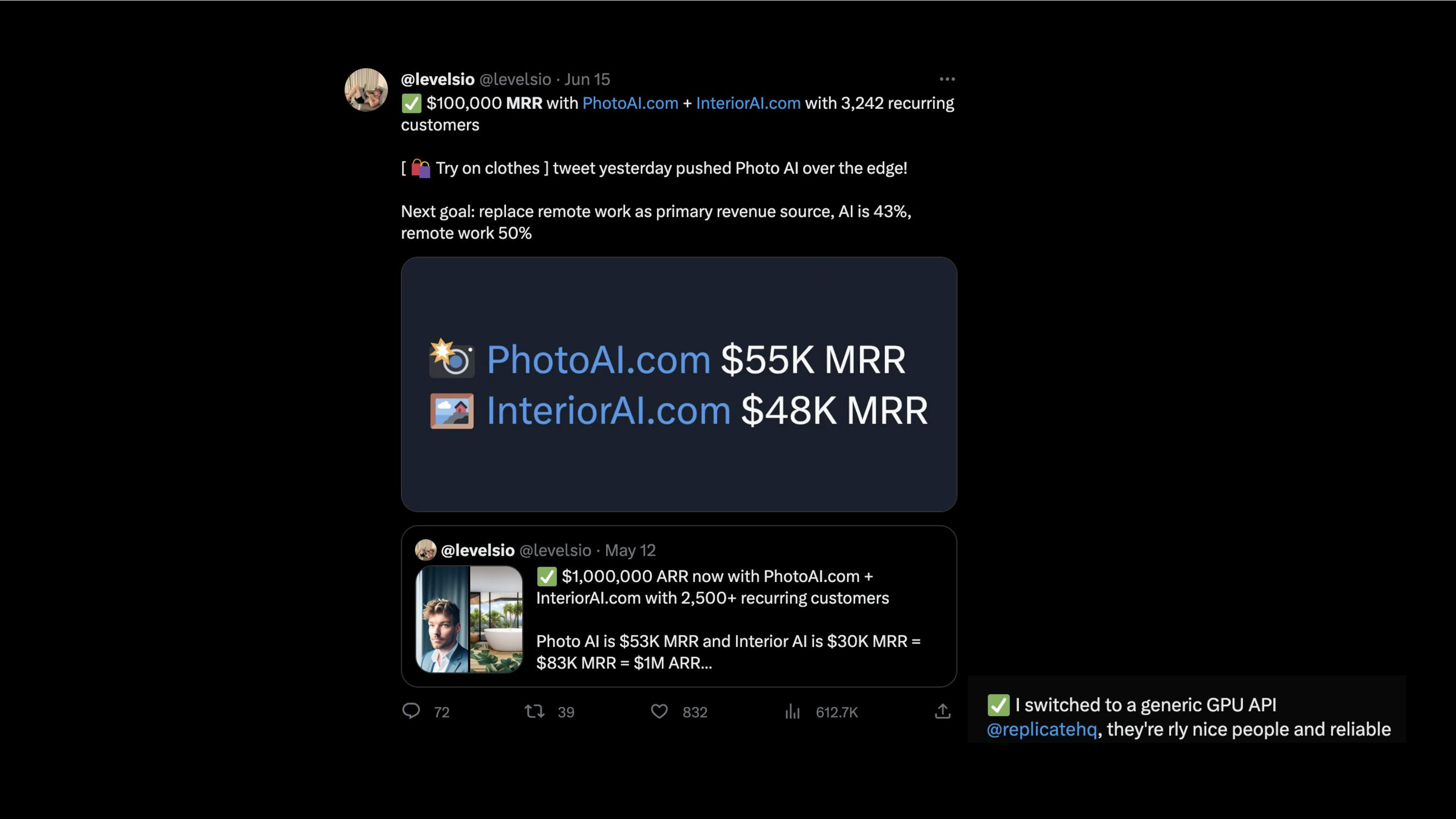
And you can go really far with just this simple looking pattern. So a simple input Magic AI box pattern. And it's not to say that this pattern isn't difficult to build apps with. It's just a simple mental model. And if you've heard of Peter Levels, he's making over $100,000 a month with his apps, Photo AI and Interior AI, which essentially take, you put in an input image and then does a bunch of upscaling and cool things to your image.
It gives you a better result. So the point is not that it's easy to build these things, but it is a really simple pattern. You can also think of ChatGPT as following this pattern. You put in a text, does something magical with that text, and gives you text back as a response. And as a side note, he is using Replicate to run his apps, which is cool. The way this looks in Elixir is actually just like what Chris was talking about using the task async library.
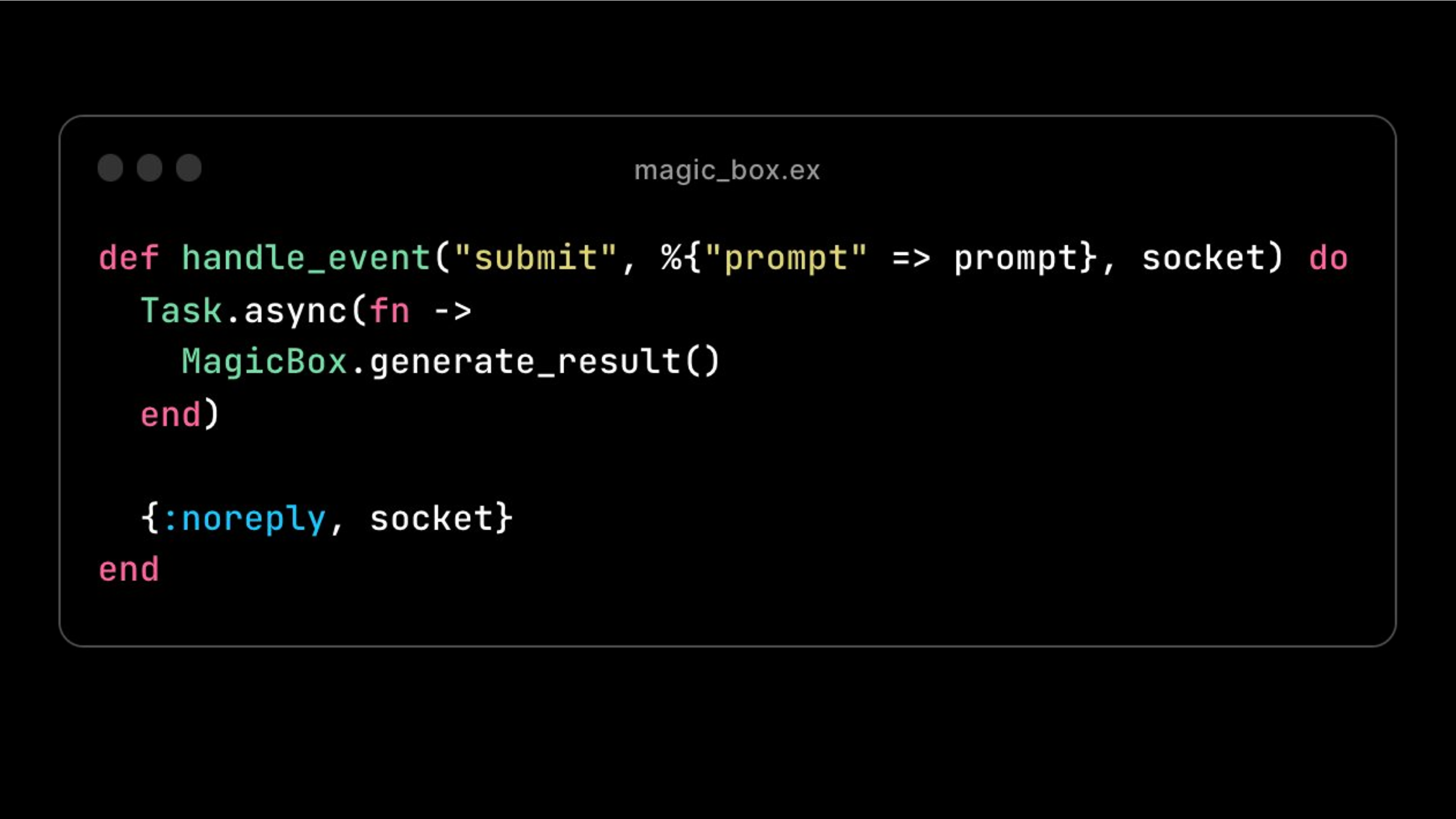
So in this case, let's say we have a form that you type in a prompt. We listen for that prompt in our handle event, set up a task async call to our, let's say, our magic box model.
![[
def handle_info({ref, result}, socket) do
Process.demonitor(ref, [:flush])
{:0k, prediction} = update_prediction(result)
{:noreply, socket |> stream_insert(:predictions, result)}
L](/elixir-conf-slides/slide-10.png)
Then we handle the info, exactly how Chris was showing us, update our prediction, and then stream in the results. So let me show you very quickly what this looks like.
📹 Magic AI Box Demo 📹
Here's a video timestamped to the Magic AI box demo.
So here we have a boilerplate Phoenix LiveView project with a form component here and a generate button. And what's going to happen is when I type an enter, we have a listener in our index LiveView file that's going to listen for the prediction, run the task.async request on generate image.
All it does is it takes in the prompt and uses, in this case, Replicate to run stable diffusion on that prompt. We're going to handle the info callback here, update the prediction, and then insert it. So it looks something like this. Let's say I say cat, press enter, and we can do something else now while it's loading.
The task is going to run it usually takes a few seconds in this case we're running stable diffusion and here we have our cat and I think this is like
This is actually really amazing. The fact that there's an Elixir primitive just called Task.async that lets us run stable diffusion and it takes 2 seconds, it takes 10 seconds and we can do other things while that's running. That is not built into other languages. I know I'm preaching to the choir here but I've had to build similar things in React or in Python and it's a lot more work and I think it's really cool how few lines I can run an asynchronous call.
I also think it's cool that I can type in a bunch of things all at once and they're going to now async in the background, render or load and then render with the associated prompt. I'll give that a second to run. Okay, see we got our turtle, match up with turtle, cat, so on.
That's the simplest possible AI app. But you can go, again, you can go really far with just this magic AI box pattern. The second pattern I want to talk about is what I call the gen server generator.

So is anyone here either a pilot or an aspiring pilot? You can raise your hand.

Okay. Okay, there's some people. So do you know what a METAR is? What's a METAR?

Exactly. Okay. So a METAR is is a way of talking about the weather in this kind of inscrutable looking code that looks like this. So this is the Orlando weather last night as I was coming in. I didn't fly myself. I just, I just looked this up. And it's, it's really hard to understand, especially if you are not a pilot. And even if you are a student pilot like me, it takes a lot of work to understand what this is even talking about.
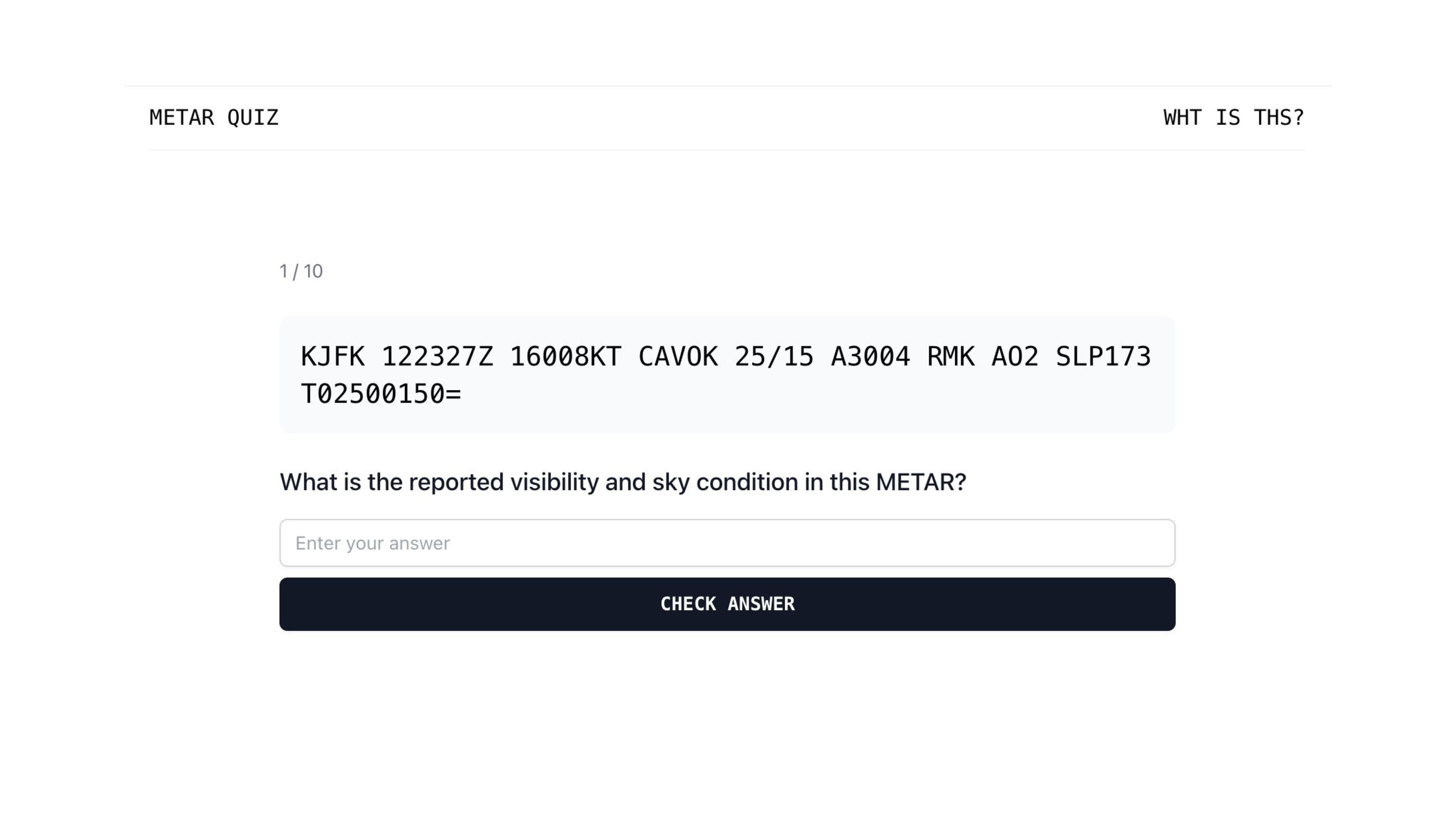
So I built a app for myself called Metar Quiz. And the way it works is it shows me a Metar, which is in the gray box, and then it asks me a question about that Metar. And there were a bunch of ways I could have populated the data for this quiz. I can actually show you.
There's a database of over 1,000 questions where here I have on the left a METAR and then on the right a question I have for that METAR. And so there are a few ways I could have populated that data. I could have done it by hand. I could have written a bunch of METARs by hand. I could have maybe found a weather API and pulled the METARs from there.
But, that would be tedious and not that fun, so what I decided to do is I used GPT-4 in this case to generate a METAR from scratch and then also generate a question about that METAR.
And so this GenServer generator pattern works really well whenever you want to build something that has a bunch of cache data that you then want to reference. And it builds that cache data using AI.
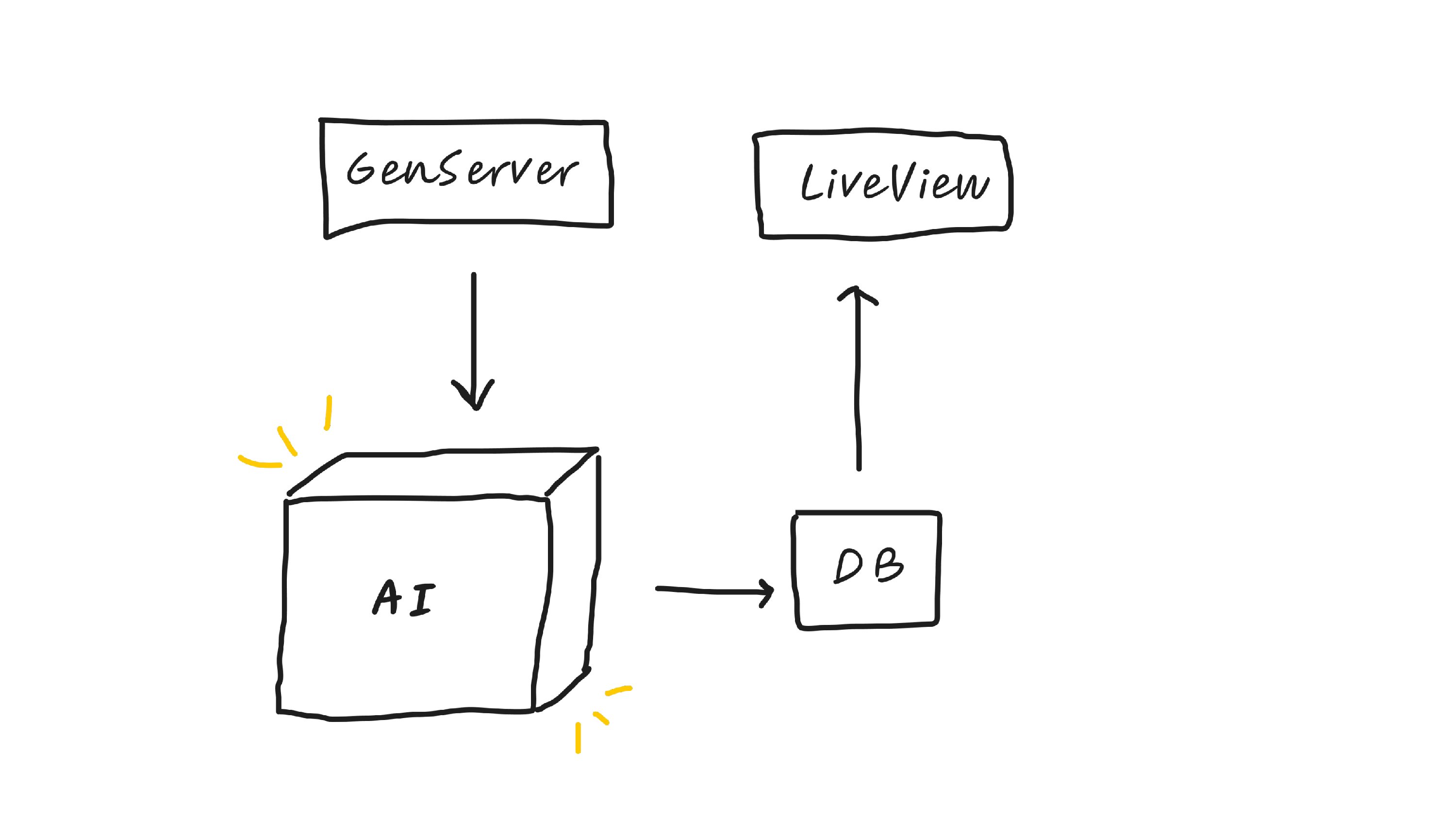
So in this case, the pattern looks like this, where we have a GenServer that calls our magical AI box, which then saves the output to a database, and then we can render it.
So up close, and again, I don't necessarily want you to worry about the code line by line. I just want you to get the gist of what this looks like. And I also will have all the code available open source after to show you. But the general idea step by step is we have a GenServer, which in this case is sending a request to itself every five seconds.
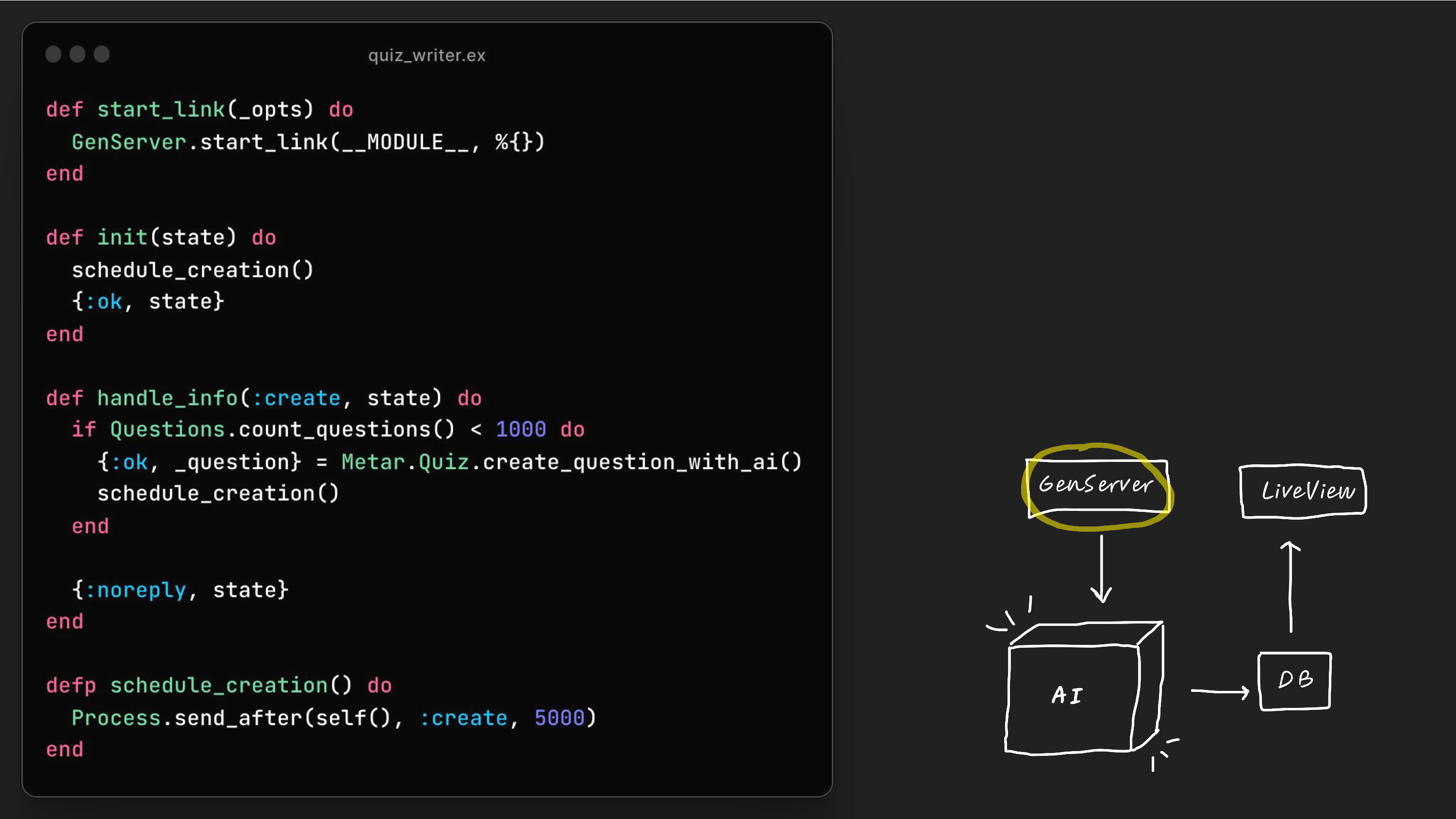
And in our handle info function, you can see if the count of the questions is under 1,000, then we will create a new question with AI. And so then we go to our magical AI box.
As a side note, when I put this out in the r slash flying subreddit, I would continually get feedback, oh, it asked a question, BR actually doesn't mean light rain, it means mist, and a lot of feedback that I could then just add to this, this text field directly, just so you know, BR means mist, not rain. And then after that, it started working again. So I could edit the code just by editing the plain text.
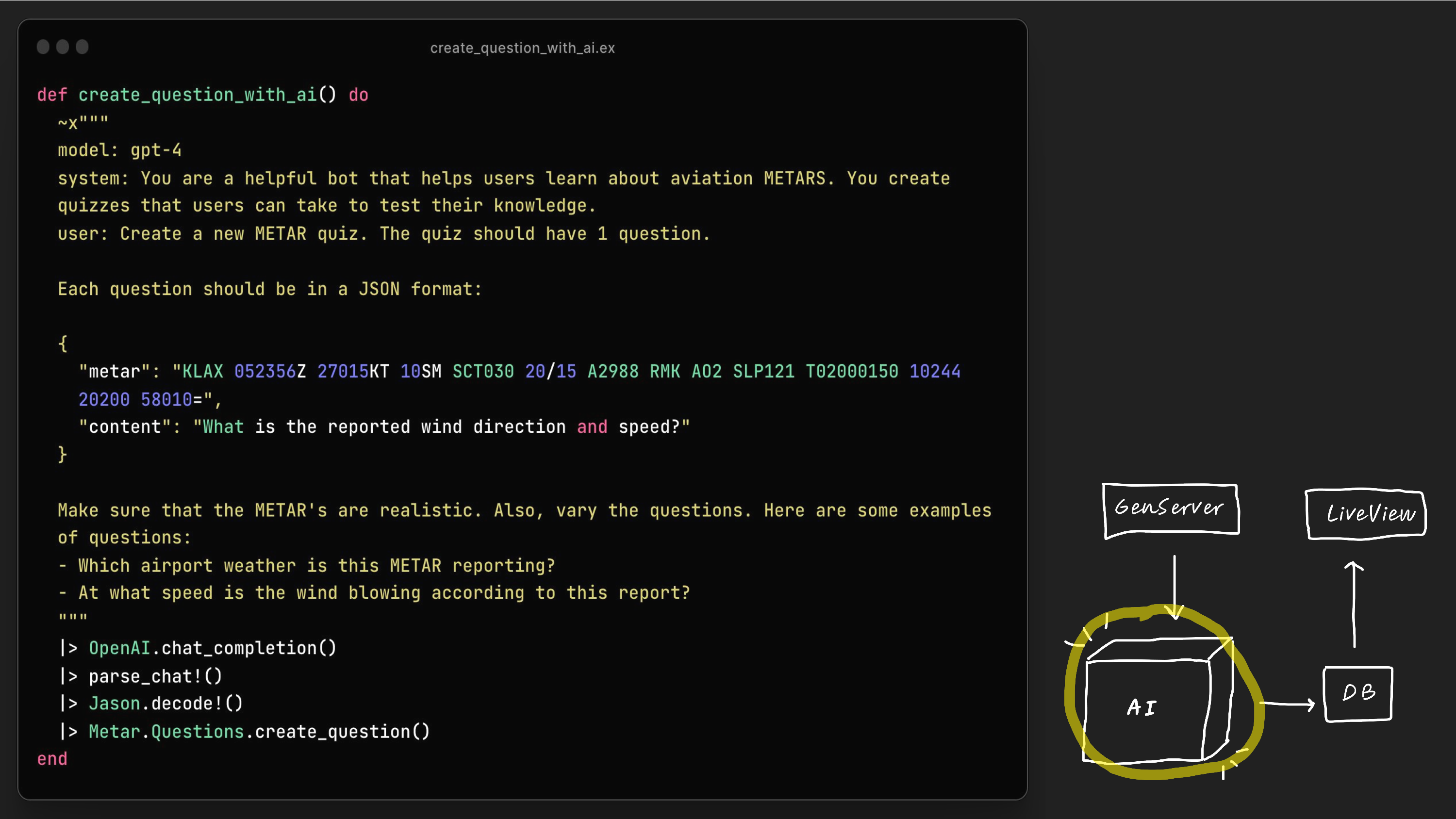
And our create_question_with_ai() function is actually mostly text. And this is another thing that I've noticed come up over and over working with AI apps, is that you'll have functions where most of the lines is text, is plain text. And this is really cool because plain text is really easy to read, and it's really easy to edit. There are downsides to having functions like this, because testing can be difficult, but I think it's mostly positive. And so in this case, our create question with AI function looks like a request. We can see on the top, it says the model is GPT-4. Then you are a helpful bot that helps users learn about aviation METARs. You create quizzes, create a new quiz, have one question in the JSON format. And then I give it a few other instructions, and then we'll get a question that we can then put in our database.
As a side note, when I put this out in the r/flying subreddit, I would continually get feedback, oh, it asked a question, BR actually doesn't mean light rain, it means mist, and a lot of feedback that I could then just add to this, this text field directly, just so you know, BR means mist, not rain. And then after that, it started working again. So I could edit the code just by editing the plain text.
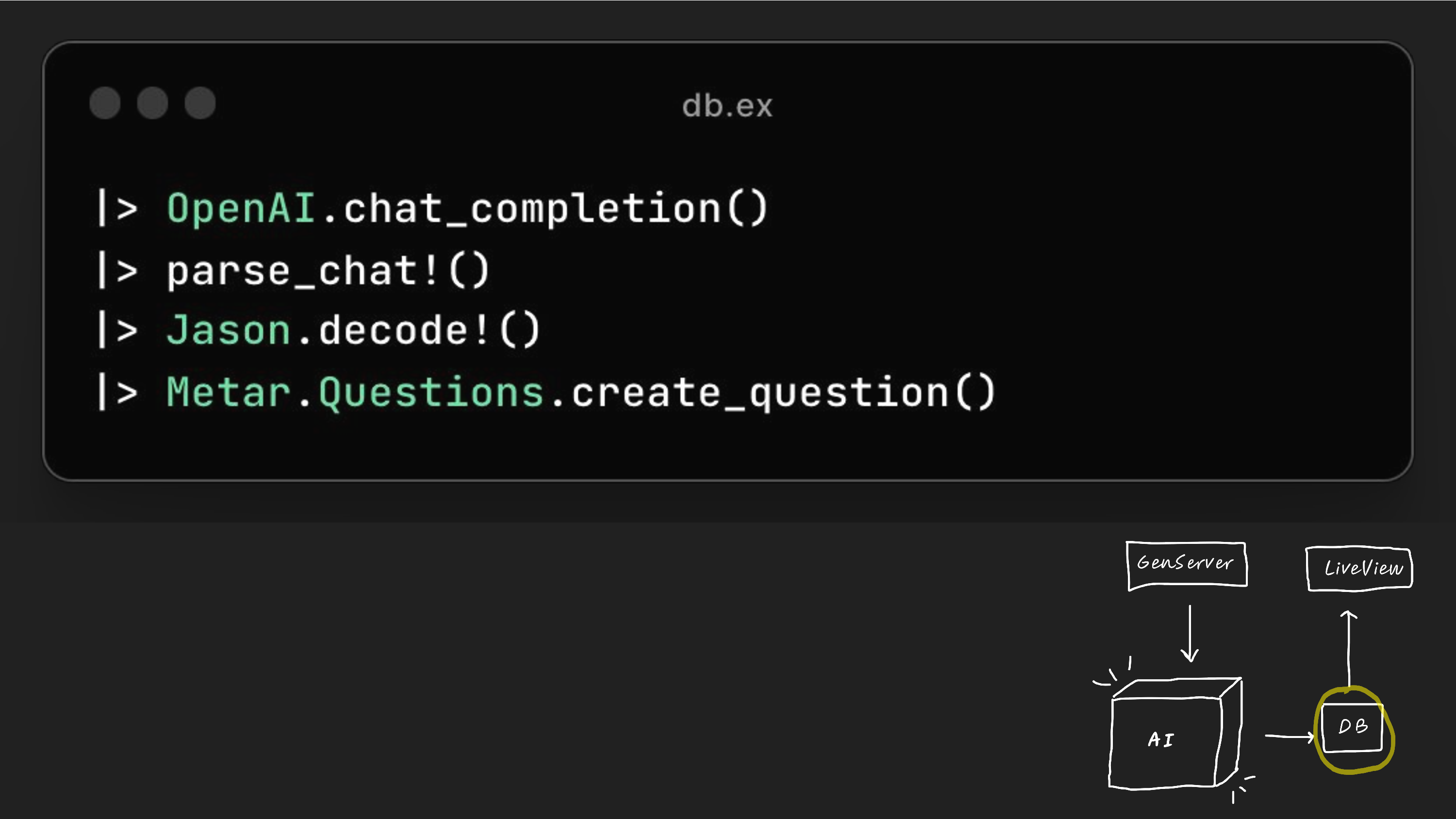
Then the next step in our pattern is we save to the DB, which is really just decoding and then creating the question in our in Ecto.
![def mount(_params, _session, socket) do
question = Questions.get_random_question()
LIS
BT 4
|> assign(quiz_length: 10, total_count: 0, correct_count: 0)
|> assign_new_question(question.id)}
CLC]
—
Ky l
@ _'](/elixir-conf-slides/slide-20.png)
And then we render it in LiveView. So the pattern is, again, it's quite straightforward, but really powerful.
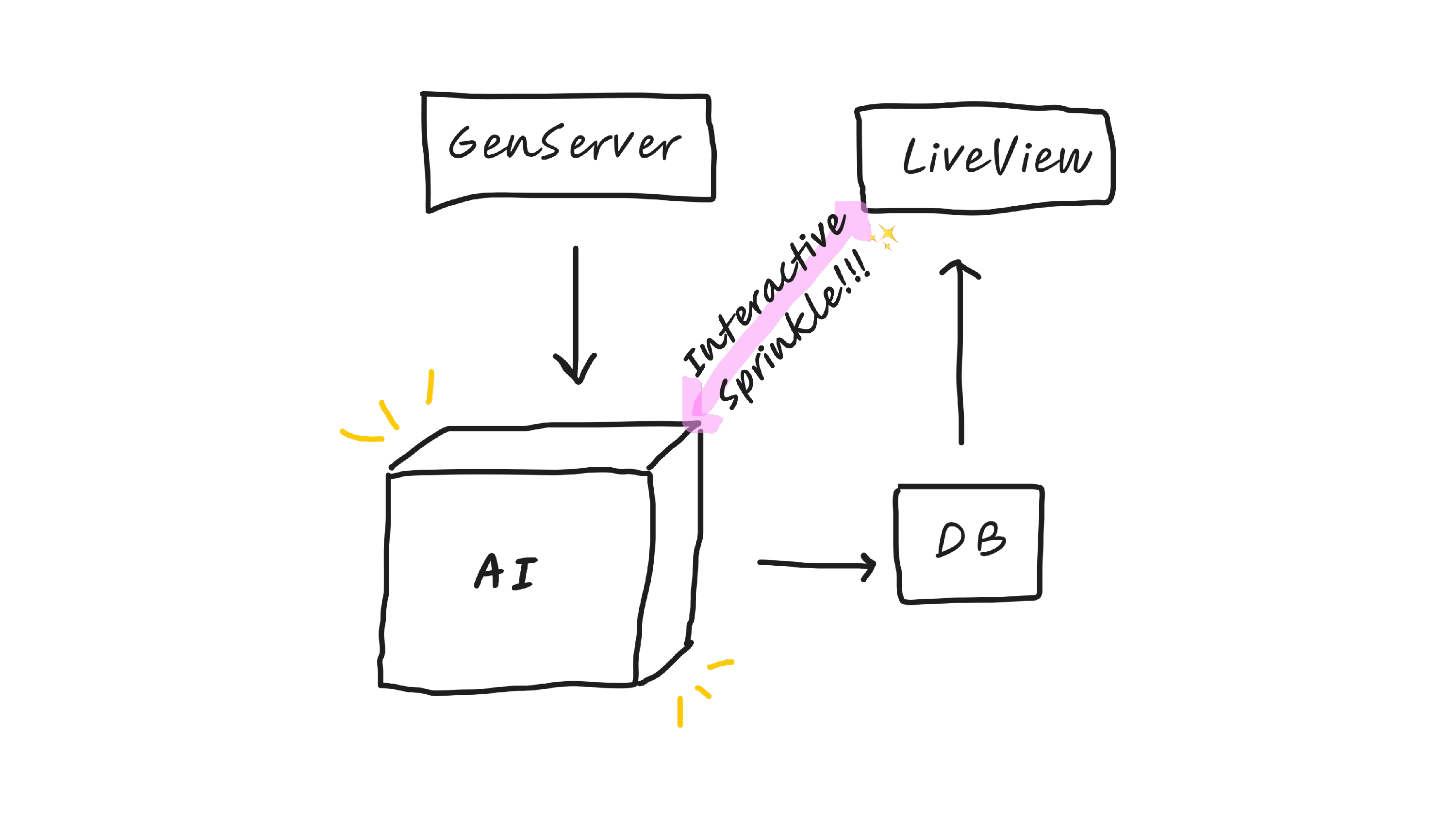
And I think it gets a step more powerful when you add what I call the interactive sprinkle. And what this means, I think this is best explained with a quick demo. And before I show you the demo, every time I type in a response to the METAR question in this case, I need some way of verifying whether the question was correct.
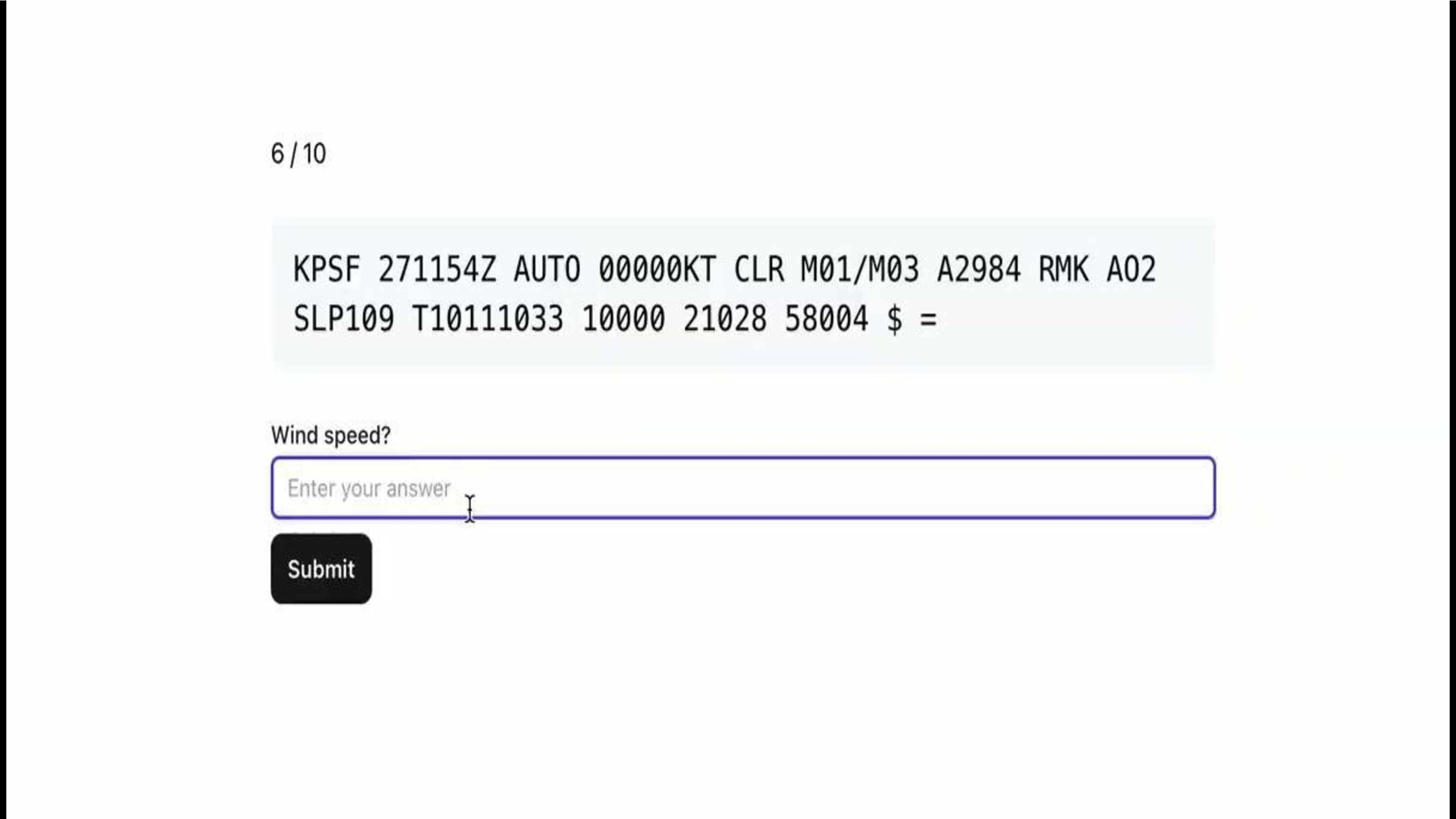
So for example, in this case we show a METAR for Pittsfield Airport and it is asking a question — wind speed?. In this case the wind speed is shown here, it is zero knots.
So there are a bunch of ways a user can answer the wind speed in this METAR. You could say zero knots, which would be correct. You could say zero KT, which would be correct. You could say zero miles an hour. You could say no wind. But as a solo developer working on something like this on the side,
It's kind of difficult or it's an interesting problem how you parse the user's input and decide whether it's correct or not. You can maybe make it multiple choice and have like C be the correct answer and then in your backend logic if the correct answer matches up then you know the answer is correct.
There are lots of ways you could solve this, but I decided to use GPT 3.5, which is another one of OpenAI models, and it's much faster than GPT-4 and much cheaper. So what happens is when a user enters an answer, in this case they say 0kt, it marks it as correct.
In this case, the user says no wind, which is marked as correct. You could say very calm, which I would say is on the cusp, but it still says it's correct. And zero miles an hour. And all those answers are correct.
And I think this makes a really nice user experience because the answer to the question is not so brittle. It's actually dynamic. It feels like there's a human on the other side that is determining whether your answer is correct or not. And the function that determines whether we're correct or not is, again, mostly text.

I call it check_answer(). And I tell GPT 3.5 Turbo, you're a helpful bot that helps the users learn about METARs.
The following question was asked about this metar. The user answered this. Are they correct? Answer in the format, true slash false, semicolon, semicolon, explanation. And the reason I use this semicolon, semicolon syntax is so that when the answer is spit out from GPT, I can split on those two semicolons and then render in the live view. This is true, and this is why it was true.
So again, we have a function that's mostly text and really easy to edit. If it starts giving true answers when it shouldn't be, I can give it more examples and it might fix it. And it's really easy to understand what's happening here.
Also, as a side note, I'm using a sigil that I made up, ~X, which maybe during the question times I will go into, but it's a nicer way to write prompts to language models.
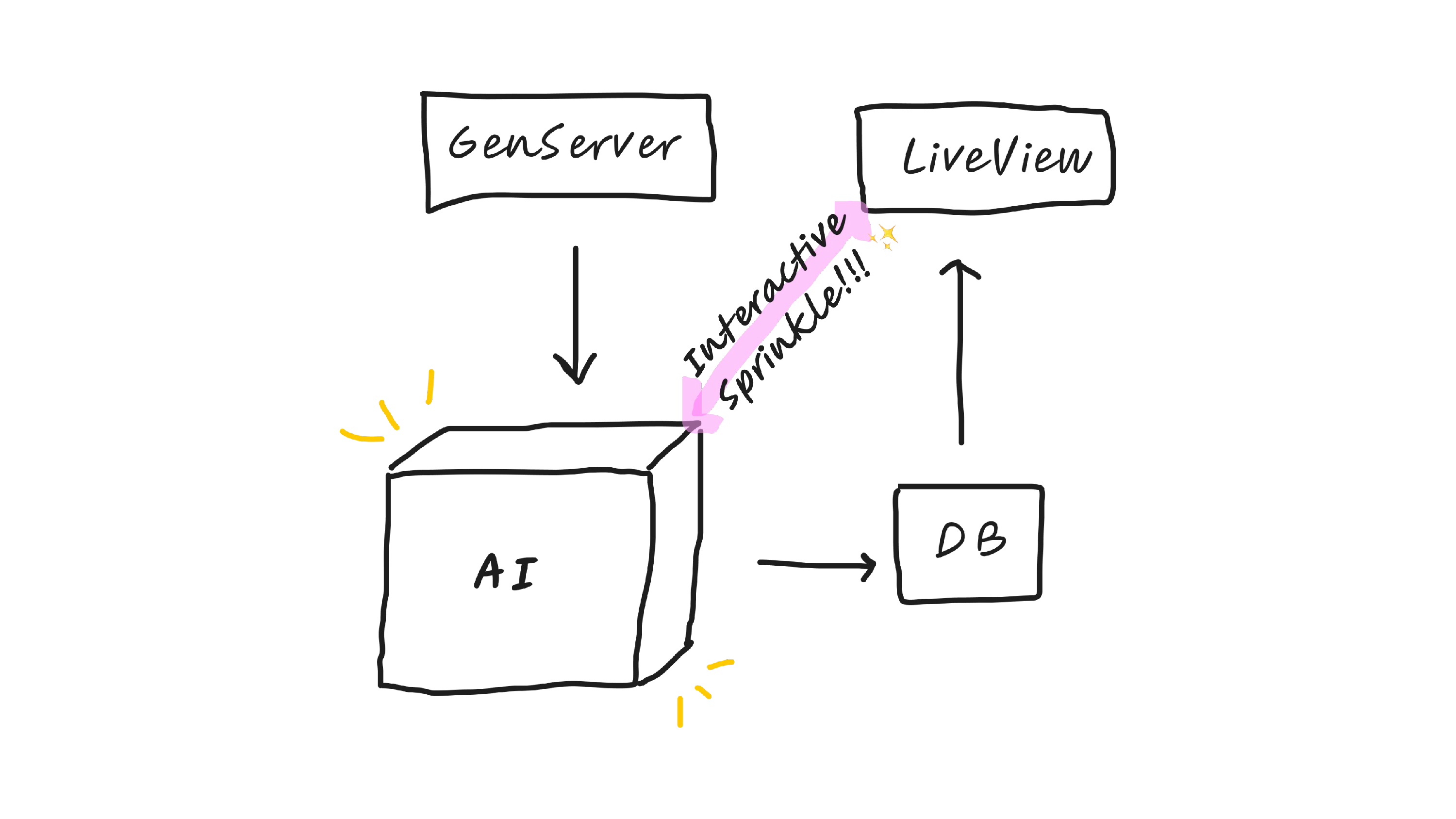
So again, we have this GenServer generator model, which can create data for us using AI, but then this interactive sprinkle, which I think is actually a really magical thing that AI has granted us, the AI gods have granted us, because as a solo developer, that specific example would have been really hard to build. But there are lots of other cool ways you can use the interactive sprinkle, like I've made a tic-tac-toe game where you bid on each square, and I realized that I could translate the tic-tac-toe game into text, into like a JSON board, and then send it to GPT, and then use GPT as an AI to play against. You could also do interactive stories and all kinds of things with the sprinkle.

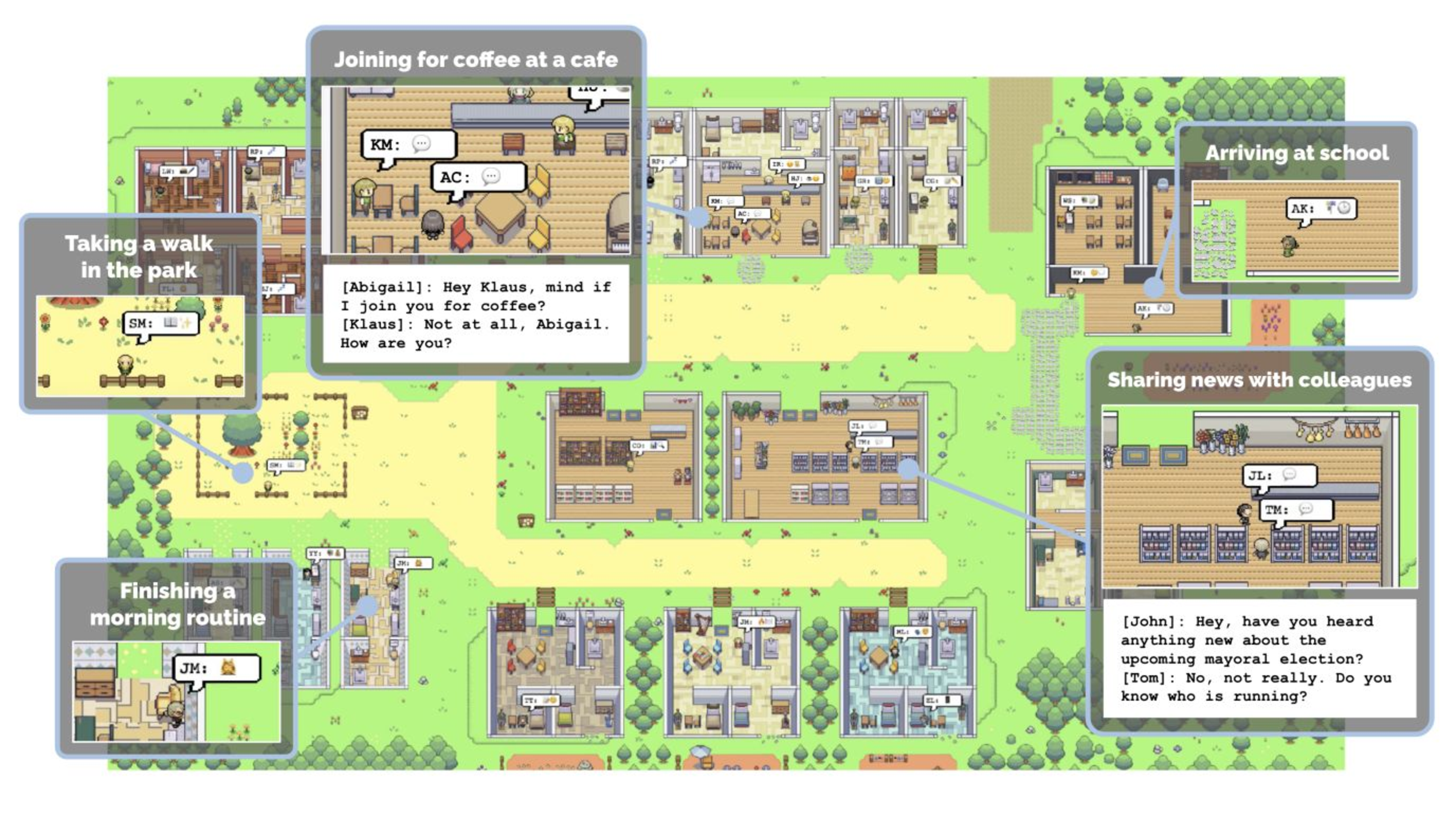
The third pattern I want to talk about I call agents. And if you're in the AI world at all, you've probably heard of what people are calling generative agents.

And so as I was reading this paper and thinking about what this means a few months ago, I was thinking about three primary things that you would need to implement this yourself. So you would need real-time updates.
You would need some kind of memory for the agents. And you would need a moderator, which is either an agent themselves or like a super moderator, like a God mode type thing that decides who speaks next and the state of the world and so on.

And so these three things are actually Elixir primitives. We have PubSub built into Elixir, which allows for real-time updates and for broadcasting and subscribing to things. We have memory, or we have state, which many languages have, but Elixir has it too. And we have supervisors, which we can use as our moderators.

And if you look at the Elixir docs talking about GenServers, we have a GenServer is a process like any other Elixir process to be used to keep state, execute code asynchronously, which we need for our AI models, and it will also fit into a supervision tree.

We even have something called an agent in Elixir, which is simplification, or it's an abstraction around genserver that allows state to be retrieved and updated by a simple AI. So I was reading this and I was like, AI agents are really hot right now, and there's a thing in Elixir called an agent that happens to have all the things you need to make a generative agent.
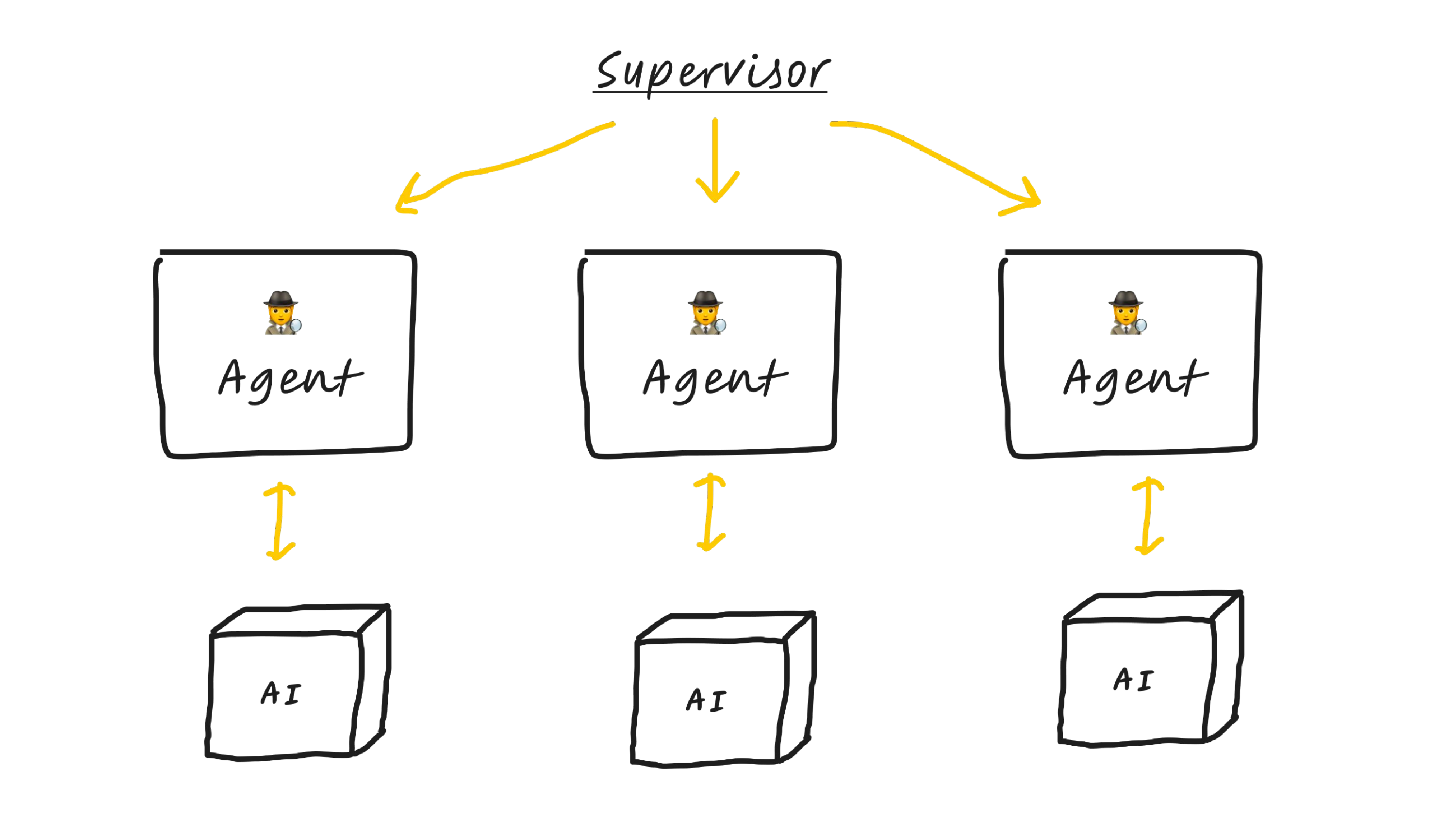
And the way I've been thinking about this pattern is I have a supervisor which manages individual AI agents, which are gen servers or elixir agents, that make calls to their own little AI magic box, which serves as their brain.
And if you zoom in on an agent, they kind of have four functions or four domains that they need to each keep track of.

So each function needs a generative AI function, which makes requests to either OpenAI or Replicate or some other service.
It needs a subscribe, which I think of as the eyes and ears of the agent, because as things are happening in the world, they get broadcast, and then the agent can listen and sense those things and then respond to them in real time.
They have a broadcast, which lines up with our subscribe, which you think of as the voice of the agent.
And then they also have just ecto, which you can think of as like the hippocampus of the agent. It's the memories, because every time something happens, it will be saved into ecto, and it can then refer to them.

So I told you briefly about ShlinkedIn. I also own shinstagram.com. And I thought this would be a perfect place to put a bunch of generative AI agents inside of and have them post pictures and respond to each other. So I'm going to show you a quick demo of what the agent model looks like.
⚠️ Note ⚠️
This part of the talk is my favorite, and really has to be seen rather than read. So here's a video timestamped to the Shinstagram demo.
So I'm going to shut that down now before it takes over the world. So to close things out, a couple of things to think about is, the first is what should you put in this magic AI box?

And these are two dependencies I now always add to my Phoenix projects. I add OpenAI and I add Replicate. I actually wrote the Replicate client.
So, I'm a fan of it. You can use thousands of open source models using the Replicate client.
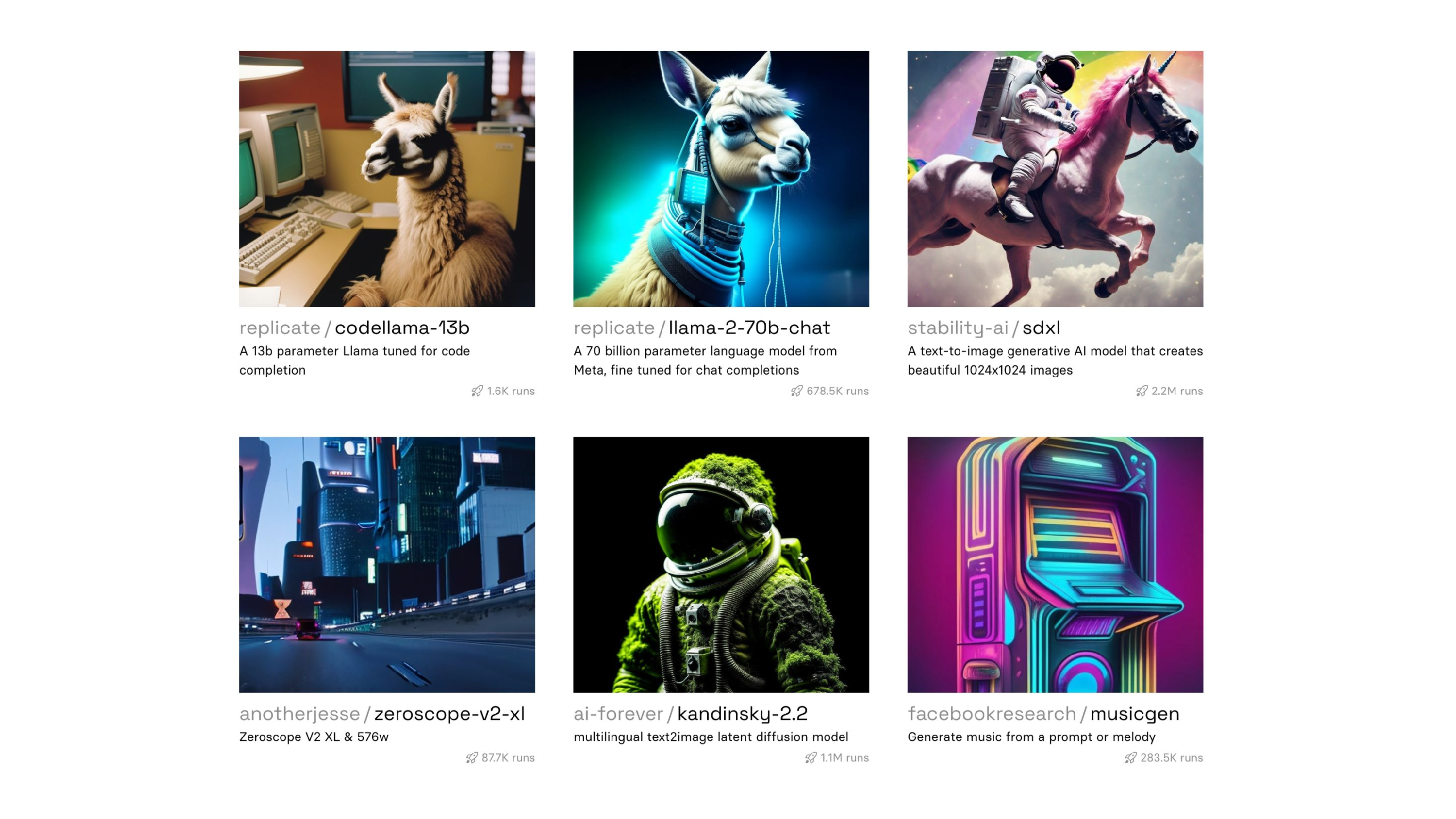
Here's a few examples from our site. These just happen to be ones we're featuring, but we have a coding generator, Code Llama, which came out from Meta recently. We have Stable Diffusion. We have MusicGen, which lets you generate music. We have Xeroscope, which can generate videos.
All kinds of things. There's so many opportunities and so many cool things you can build with these models right now.

And it happens to be that Elixir is really good at doing that. So just to repeat again, we have these three patterns, the magic AI box, the gen server generator for generating data with an interactive sprinkle, and we have agents.

Elixir primitives are great for AI, so hopefully this gets more people talking about the ways you can use Elixir and AI. And I think as Elixir developers, and LiveView developers too, we're really lucky in that all our primitives happen to line up well with this AI world.
I hope you enjoyed this, and that it inspires you to build cool AI projects yourself.
Thanks to...
Huge thanks to @anotherjesse, @jakedahn, @GiladSeckler, for helping me think through this talk. And thanks to Jose for letting me use him as my Shinstagram test subject :)
Questions? Feedback?
Reach out to me on Twitter/X!